

컴퓨터 네트워크 08 : 라우팅
라우터: 다른 네트워크와의 연결을 통해 패킷을 전송할 수 있도록 하는 장치. 목적지까진의 경로를 설정해주는 역할을 한다.
라우팅 알고리즘의 목표는 송신자로부터 수신자까지 라우터의 네트워크를 통과할 때의 최소 비용 경로를 결정하는 것이다.
라우팅 알고리즘의 분류
중앙 집중형 vs 분산형
중앙 집중형
네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이 최소 비용 경로를 계산하는 알고리즘.
연결과 링크 비용에 대한 완전한 정보를 가져야한다. 이를 Link-State, LS 알고리즘이라고 한다.
분산형
최소 비용 경로의 계산이 라우터들에 의해 반복적이고 분산된 방식으로 수행된다. 어떤 노드도 모든 링크의 비용에 대한 완전한 정보를 갖고 있지 않다. 각 노드는 자신에게 직접 연결된 링크에 대한 비용 정보만을 가지고 시작한다.
이후, 반복된 계산과 이웃 노드와의 정보 교환을 통해 노드는 점차적으로 목적지 또는 목적지 집합까지의 최소 비용 경로를 계산한다.
이러한 방식을 Distance-Vector DV 알고리즘이라고 한다.
정적 vs 동적
정적 라우팅
패킷 전송이 이루어지기 전 경로 정보를 라우터가 미리 저장하여 중계한다.
경로가 아주 느리게 변하고 네트워크 변화와 혼잡도에 대한 대처가 어렵다.
동적 라우팅
라우터 경로 정보가 네트워크 상황에 따라 적절히 조절된다.
경로 정보 수집과 관리로 인해 성능 저하가 나타나는 단점이 있다.
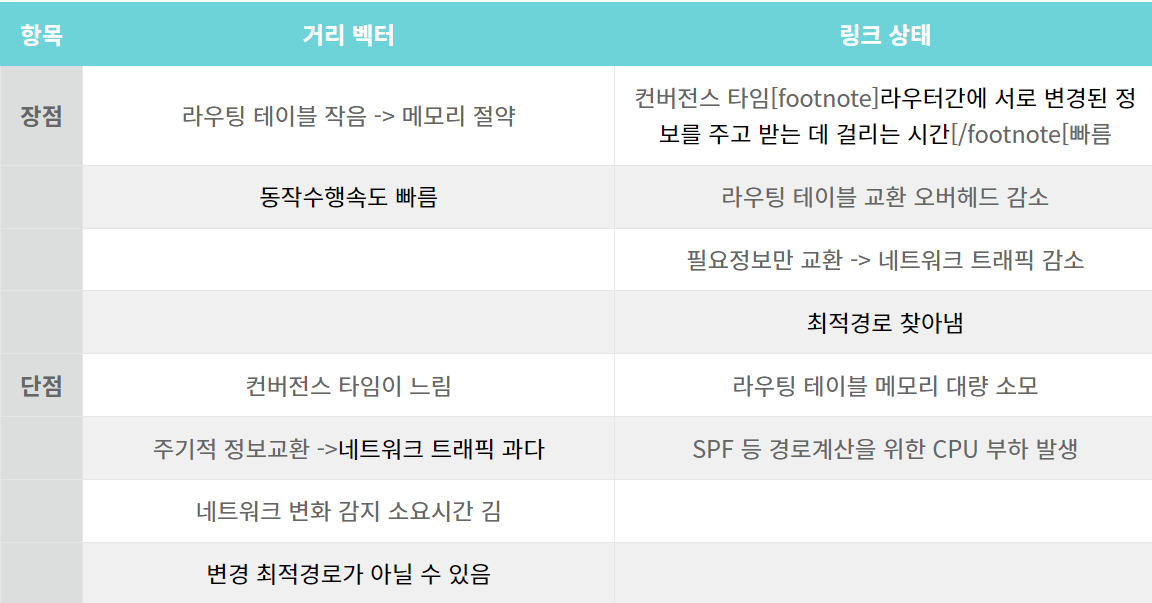
LS 알고리즘 vs DV 알고리즘
LS 알고리즘: 링크 상태 알고리즘
모든 링크에 대한 비용이 알려져 있기 때문에 다익스트라 알고리즘이라고도 부른다.
거리와 대역폭에 따라 경로를 계산하고 라우팅 정보 변화시 변경 정보를 전달하는 장점이 있다.
그러나 모든 라우팅 정보를 관리하기 때문에 메모리 소모와 CPU로드 소요 문제를 가지고 있다.
대규모 네트워크에 적합하며, 이벤트 기반으로 라우팅 테이블을 갱신한다. 인접 라우터와 링크 상태 정보를 교환하는 식으로 정보 교환이 이루어진다.
DV 알고리즘: 거리 벡터 알고리즘
거리와 방향만을 위주로 만들어졌다.
라우터는 목적지까지의 거리와 그 목적지까지 가려면 어떤 인접 라우터를 거쳐야하는지에 대한 정보만 저장한다.
각 노드는 하나 이상의 직접 연결된 이웃이 주는 정보로 계산하고 이웃에게 계산 결과를 알린다는 점에서 분산적이고, 이웃끼리 정보를 교환하지 않을 때까지 프로세스가 지속된다는 점에서 반복적이며, 모든 노드가 서로 톱니바퀴 모드로 동작할 필요가 없다는 점에서 비동기적이다.
가장 대표적으로 벨만-포드 알고리즘이 있다.
라우팅 테이블의 크기가 작아서 메모리를 절약할 수 있고 구성이 간단하다는 장점을 가진다.
반면, 주기적으로 라우팅 정보를 갱신하여 트래픽이 낭비되고 라우팅 정보 변화시 전달이 느린 단점이 있다.
소규모 네트워크에 적합하며, 인접 라우터와 거리 정보를 교환하는 식으로 라우팅 정보를 교환한다.

'CS 공부 > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 10 : 데이터 링크 계층과 이더넷 프로토콜 (0) | 2023.04.28 |
|---|---|
| 컴퓨터 네트워크 09 : NAT (0) | 2023.04.07 |
| 컴퓨터 네트워크 07 : 네트워크 계층, IP 주소의 구조, 서브넷 (0) | 2023.04.07 |
| 컴퓨터 네트워크 06 : TCP 흐름제어, 혼잡 제어 (0) | 2023.03.31 |
| 컴퓨터 네트워크 05 : TCP UDP (0) | 2023.03.31 |